인공지능강의
05. PART 4) 딥러닝의 3 STEP의 기초
59. 맥락을 파악하는 Attention 기법 - 08. (STEP 3) Attention 신경망 구현 및 학습 - 2
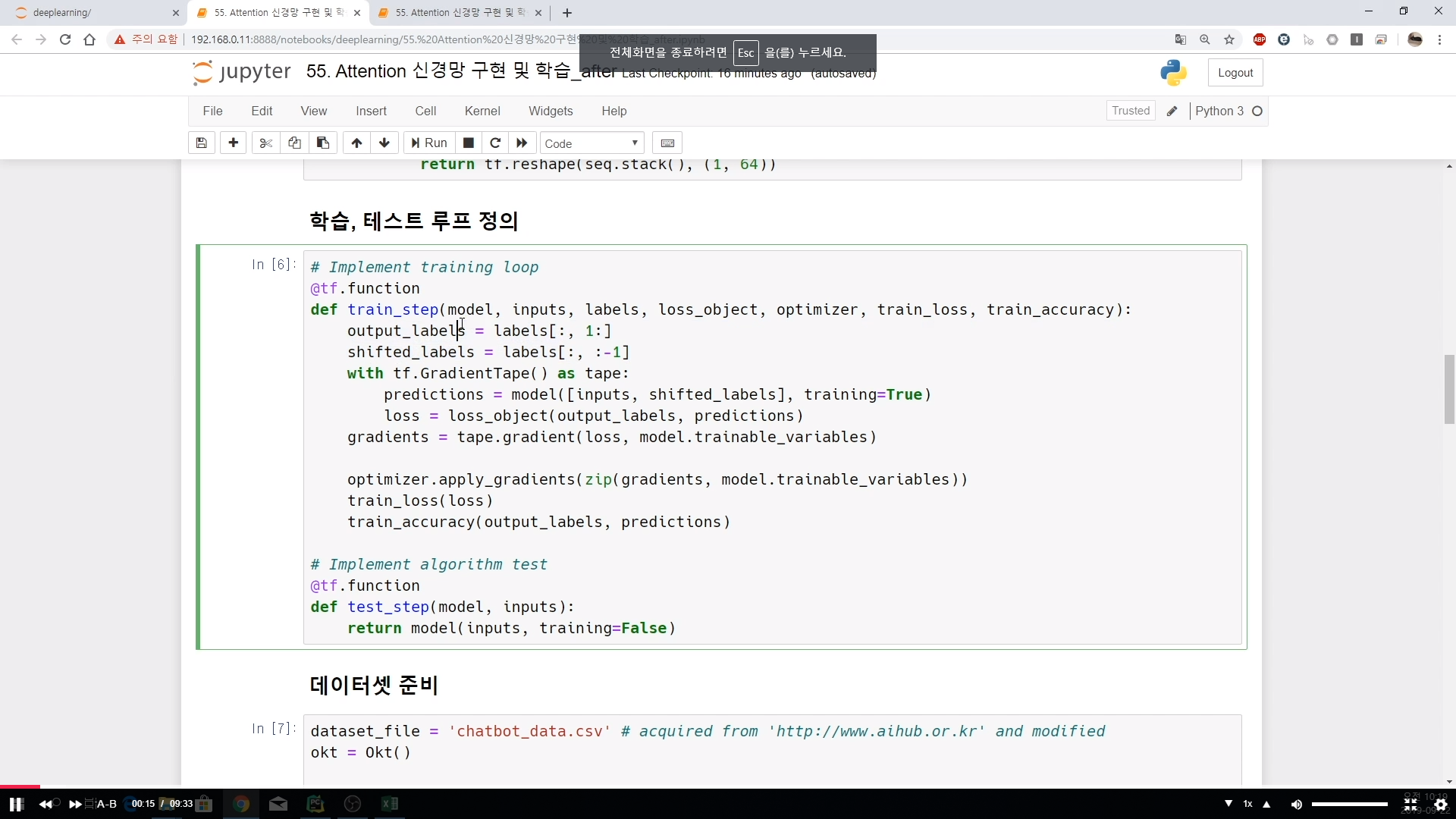
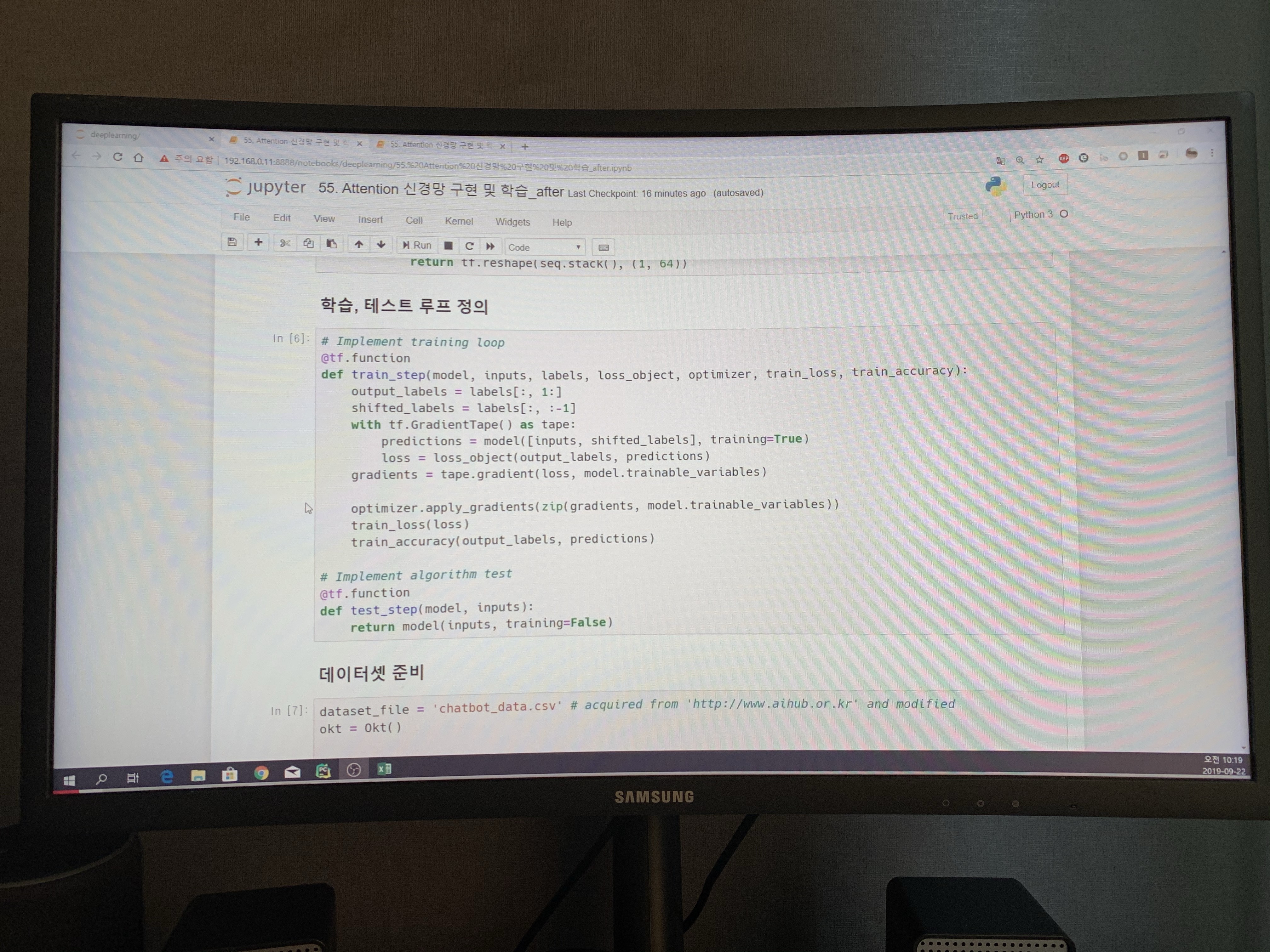
## 학습, 테스트 루프 정의
# Implement training loop
@tf.function
def train_step(model, inputs, labels, loss_object, optimizer, train_loss, train_accuracy):
output_labels = labels[:, 1:]
shifted_labels = labels[:, :-1]
with tf.GradientTape() as tape:
predictions = model([inputs, shifted_labels], training=True)
loss = loss_object(output_labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(output_labels, predictions)
# Implement algorithm test
@tf.function
def test_step(model, inputs):
return model(inputs, training=False)
## 데이터셋 준비
dataset_file = 'chatbot_data.csv' # acquired from 'http://www.aihub.or.kr' and modified
okt = Okt()
with open(dataset_file, 'r') as file:
lines = file.readlines()
seq = [' '.join(okt.morphs(line)) for line in lines]
questions = seq[::2]
answers = ['\t ' + lines for lines in seq[1::2]]
num_sample = len(questions)
perm = list(range(num_sample))
random.seed(0)
random.shuffle(perm)
train_q = list()
train_a = list()
test_q = list()
test_a = list()
for idx, qna in enumerate(zip(questions, answers)):
q, a = qna
if perm[idx] > num_sample//5:
train_q.append(q)
train_a.append(a)
else:
test_q.append(q)
test_a.append(a)
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=NUM_WORDS,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~')
tokenizer.fit_on_texts(train_q + train_a)
train_q_seq = tokenizer.texts_to_sequences(train_q)
train_a_seq = tokenizer.texts_to_sequences(train_a)
test_q_seq = tokenizer.texts_to_sequences(test_q)
test_a_seq = tokenizer.texts_to_sequences(test_a)
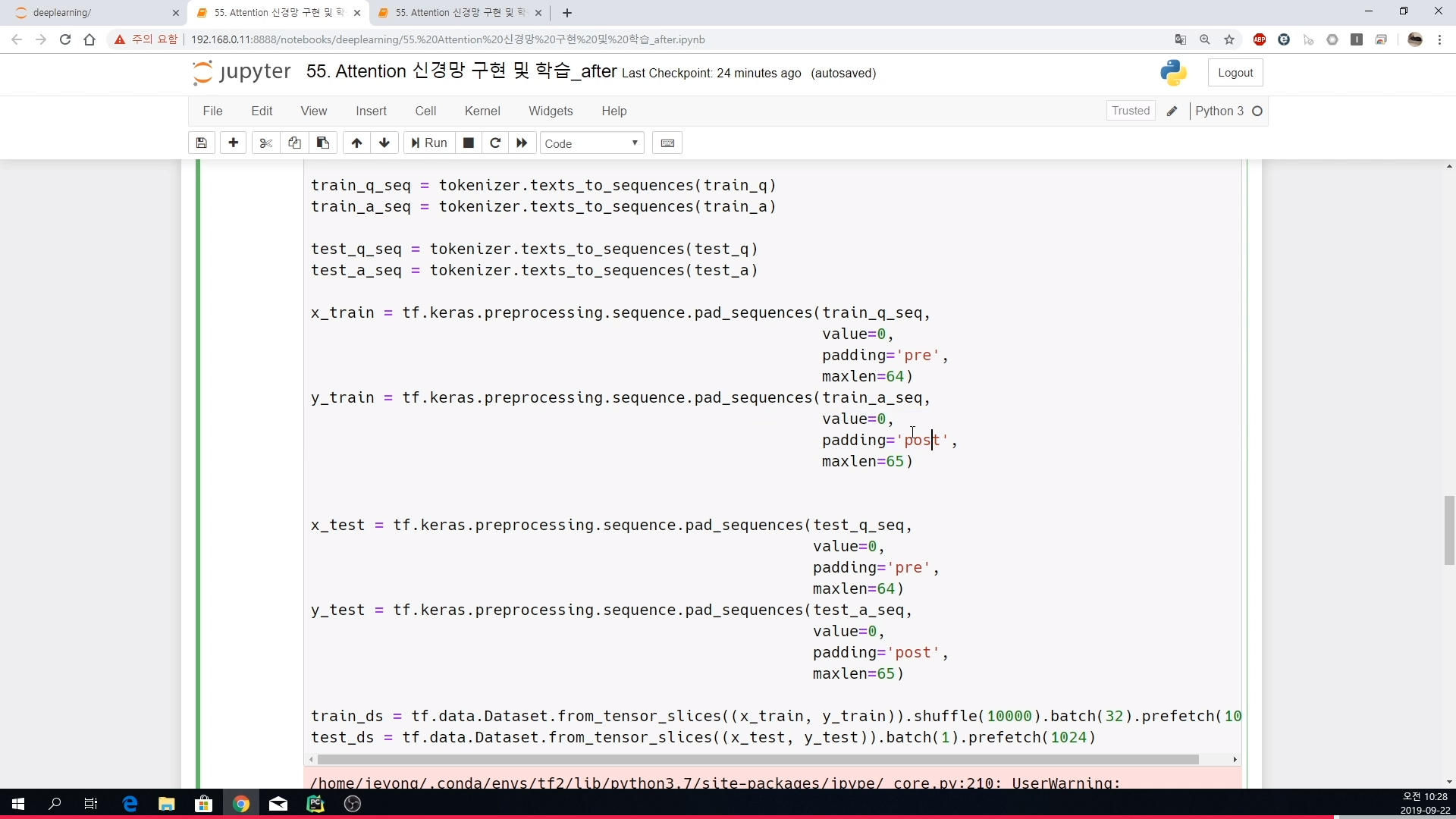
x_train = tf.keras.preprocessing.sequence.pad_sequences(train_q_seq,
value=0,
padding='pre',
maxlen=64)
y_train = tf.keras.preprocessing.sequence.pad_sequences(train_a_seq,
value=0,
padding='post',
maxlen=65)
x_test = tf.keras.preprocessing.sequence.pad_sequences(test_q_seq,
value=0,
padding='pre',
maxlen=64)
y_test = tf.keras.preprocessing.sequence.pad_sequences(test_a_seq,
value=0,
padding='post',
maxlen=65)
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32).prefetch(1024)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(1).prefetch(1024)
## 학습 환경 정의
### 모델 생성, 손실함수, 최적화 알고리즘, 평가지표 정의
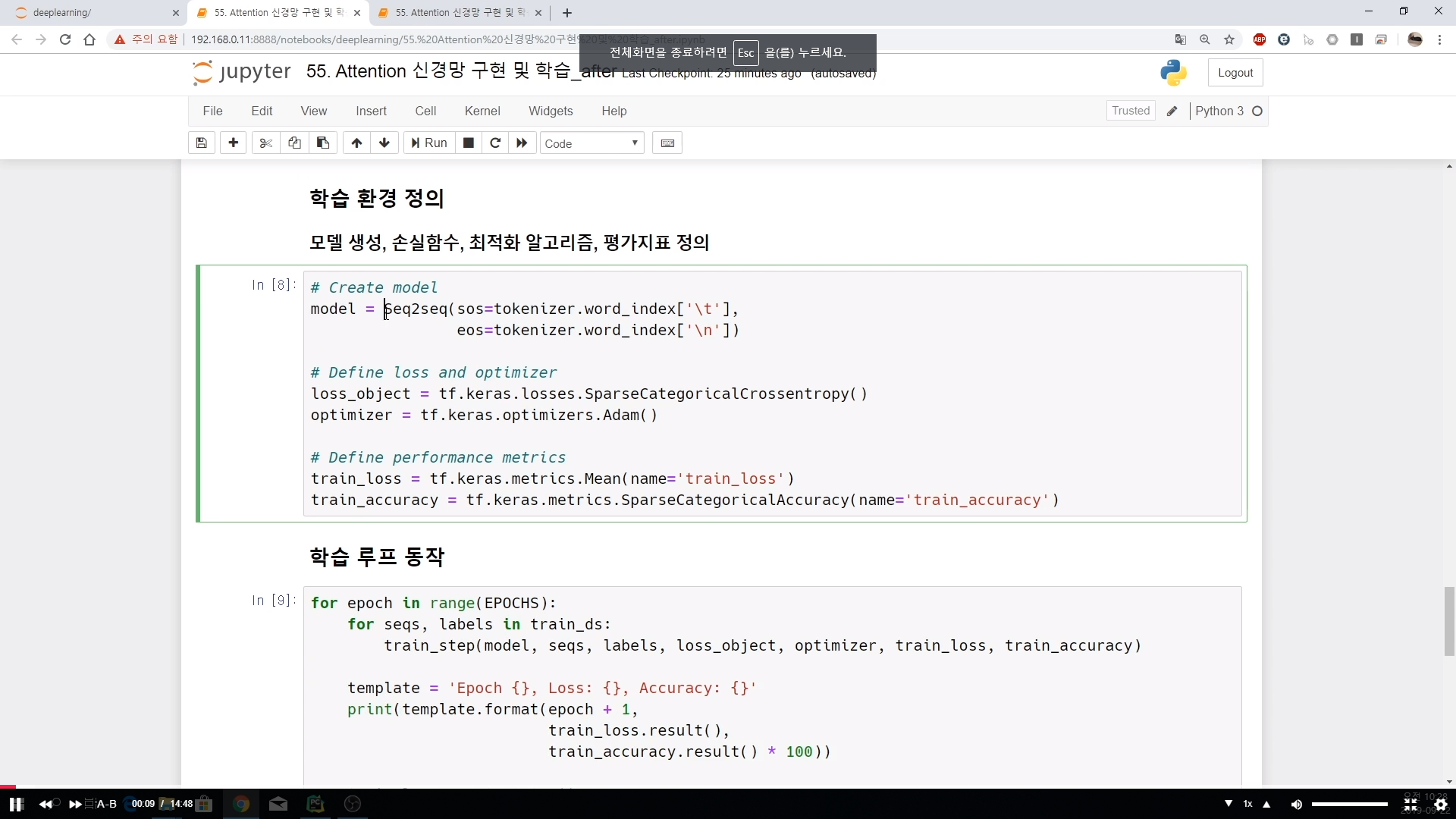
# Create model
model = Seq2seq(sos=tokenizer.word_index['\t'],
eos=tokenizer.word_index['\n'])
# Define loss and optimizer
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
# Define performance metrics
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
## 학습 루프 동작
for epoch in range(EPOCHS):
for seqs, labels in train_ds:
train_step(model, seqs, labels, loss_object, optimizer, train_loss, train_accuracy)
template = 'Epoch {}, Loss: {}, Accuracy: {}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100))
train_loss.reset_states()
train_accuracy.reset_states()
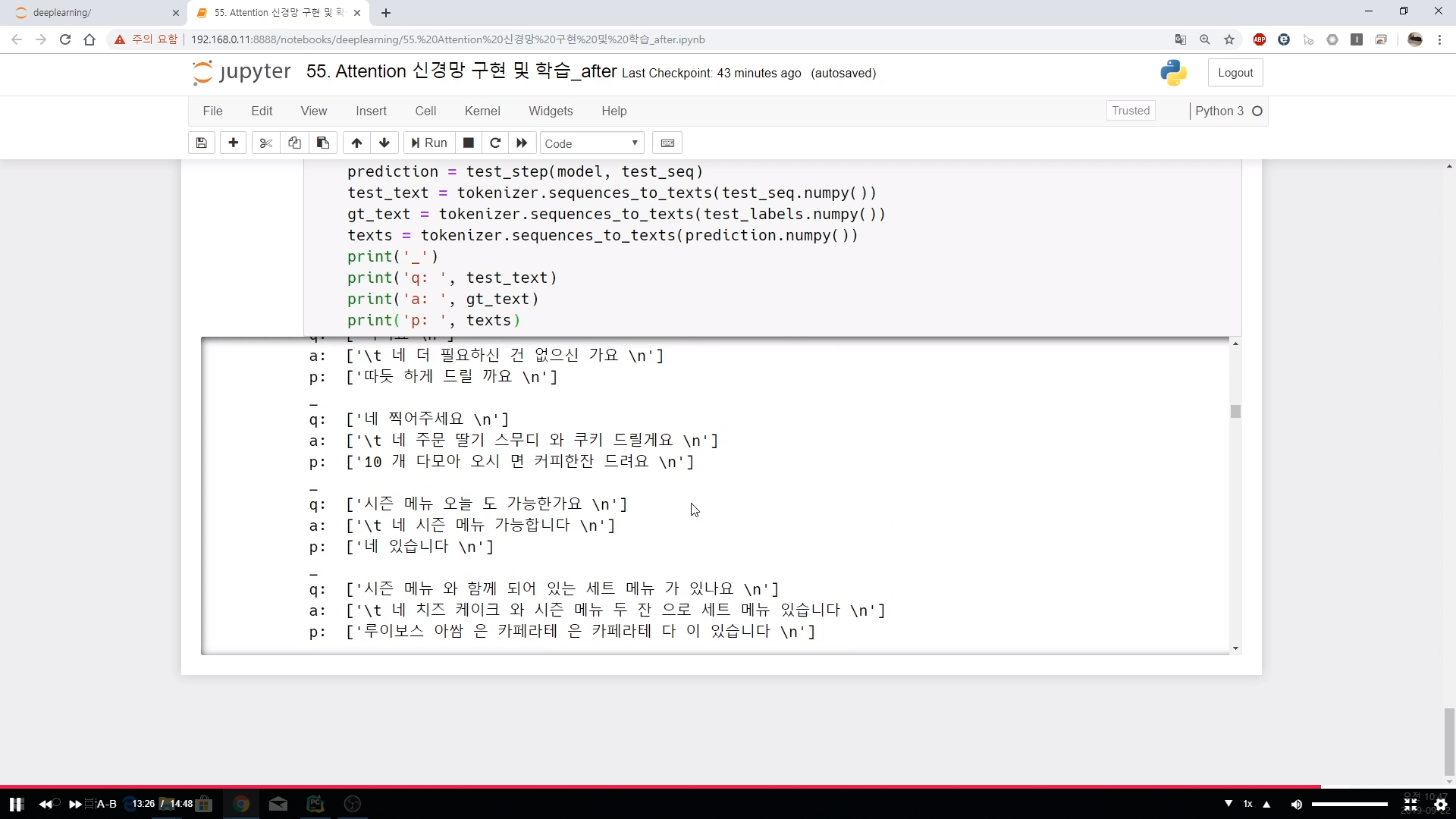
## 테스트 루프
for test_seq, test_labels in test_ds:
prediction = test_step(model, test_seq)
test_text = tokenizer.sequences_to_texts(test_seq.numpy())
gt_text = tokenizer.sequences_to_texts(test_labels.numpy())
texts = tokenizer.sequences_to_texts(prediction.numpy())
print('_')
print('q: ', test_text)
print('a: ', gt_text)
print('p: ', texts)
60. 맥락을 파악하는 Attention 기법 - 09. (STEP 3) Attention 신경망 구현 및 학습 - 3
## Attention 신경망 구현 및 학습
import random
import tensorflow as tf
from konlpy.tag import Okt
## 하이퍼 파라미터
EPOCHS = 200
NUM_WORDS = 2000
## Encoder
class Encoder(tf.keras.Model):
def __init__(self):
super(Encoder, self).__init__()
self.emb = tf.keras.layers.Embedding(NUM_WORDS, 64)
self.lstm = tf.keras.layers.LSTM(512, return_sequences=True, return_state=True)
def call(self, x, training=False, mask=None):
x = self.emb(x)
H, h, c = self.lstm(x)
return H, h, c
## Decoder
class Decoder(tf.keras.Model):
def __init__(self):
super(Decoder, self).__init__()
self.emb = tf.keras.layers.Embedding(NUM_WORDS, 64)
self.lstm = tf.keras.layers.LSTM(512, return_sequences=True, return_state=True)
self.att = tf.keras.layers.Attention()
self.dense = tf.keras.layers.Dense(NUM_WORDS, activation='softmax')
def call(self, inputs, training=False, mask=None):
x, s0, c0, H = inputs
x = self.emb(x)
S, h, c = self.lstm(x, initial_state=[s0, c0])
S_ = tf.concat([s0[:, tf.newaxis, :], S[:, :-1, :]], axis=1)
A = self.att([S_, H])
y = tf.concat([S, A], axis=-1)
return self.dense(y), h, c
## Seq2seq
class Seq2seq(tf.keras.Model):
def __init__(self, sos, eos):
super(Seq2seq, self).__init__()
self.enc = Encoder()
self.dec = Decoder()
self.sos = sos
self.eos = eos
def call(self, inputs, training=False, mask=None):
if training is True:
x, y = inputs
H, h, c = self.enc(x)
y, _, _ = self.dec((y, h, c, H))
return y
else:
x = inputs
H, h, c = self.enc(x)
y = tf.convert_to_tensor(self.sos)
y = tf.reshape(y, (1, 1))
seq = tf.TensorArray(tf.int32, 64)
for idx in tf.range(64):
y, h, c = self.dec([y, h, c, H])
y = tf.cast(tf.argmax(y, axis=-1), dtype=tf.int32)
y = tf.reshape(y, (1, 1))
seq = seq.write(idx, y)
if y == self.eos:
break
return tf.reshape(seq.stack(), (1, 64))
## 학습, 테스트 루프 정의
# Implement training loop
@tf.function
def train_step(model, inputs, labels, loss_object, optimizer, train_loss, train_accuracy):
output_labels = labels[:, 1:]
shifted_labels = labels[:, :-1]
with tf.GradientTape() as tape:
predictions = model([inputs, shifted_labels], training=True)
loss = loss_object(output_labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(output_labels, predictions)
# Implement algorithm test
@tf.function
def test_step(model, inputs):
return model(inputs, training=False)
## 데이터셋 준비
dataset_file = 'chatbot_data.csv' # acquired from 'http://www.aihub.or.kr' and modified
okt = Okt()
with open(dataset_file, 'r') as file:
lines = file.readlines()
seq = [' '.join(okt.morphs(line)) for line in lines]
questions = seq[::2]
answers = ['\t ' + lines for lines in seq[1::2]]
num_sample = len(questions)
perm = list(range(num_sample))
random.seed(0)
random.shuffle(perm)
train_q = list()
train_a = list()
test_q = list()
test_a = list()
for idx, qna in enumerate(zip(questions, answers)):
q, a = qna
if perm[idx] > num_sample//5:
train_q.append(q)
train_a.append(a)
else:
test_q.append(q)
test_a.append(a)
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=NUM_WORDS,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~')
tokenizer.fit_on_texts(train_q + train_a)
train_q_seq = tokenizer.texts_to_sequences(train_q)
train_a_seq = tokenizer.texts_to_sequences(train_a)
test_q_seq = tokenizer.texts_to_sequences(test_q)
test_a_seq = tokenizer.texts_to_sequences(test_a)
x_train = tf.keras.preprocessing.sequence.pad_sequences(train_q_seq,
value=0,
padding='pre',
maxlen=64)
y_train = tf.keras.preprocessing.sequence.pad_sequences(train_a_seq,
value=0,
padding='post',
maxlen=65)
x_test = tf.keras.preprocessing.sequence.pad_sequences(test_q_seq,
value=0,
padding='pre',
maxlen=64)
y_test = tf.keras.preprocessing.sequence.pad_sequences(test_a_seq,
value=0,
padding='post',
maxlen=65)
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32).prefetch(1024)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(1).prefetch(1024)
#%% md
## 학습 환경 정의
### 모델 생성, 손실함수, 최적화 알고리즘, 평가지표 정의
# Create model
model = Seq2seq(sos=tokenizer.word_index['\t'],
eos=tokenizer.word_index['\n'])
# Define loss and optimizer
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
# Define performance metrics
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
## 학습 루프 동작
for epoch in range(EPOCHS):
for seqs, labels in train_ds:
train_step(model, seqs, labels, loss_object, optimizer, train_loss, train_accuracy)
template = 'Epoch {}, Loss: {}, Accuracy: {}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100))
train_loss.reset_states()
train_accuracy.reset_states()
## 테스트 루프
for test_seq, test_labels in test_ds:
prediction = test_step(model, test_seq)
test_text = tokenizer.sequences_to_texts(test_seq.numpy())
gt_text = tokenizer.sequences_to_texts(test_labels.numpy())
texts = tokenizer.sequences_to_texts(prediction.numpy())
print('_')
print('q: ', test_text)
print('a: ', gt_text)
print('p: ', texts)
딥러닝/인공지능 올인원 패키지 Online. | 패스트캠퍼스
Tensorflow2.0부터 Pytorch까지 딥러닝 대표 프레임워크를 정복하기. 생활 깊숙이 침투한 인공지능, 그 중심엔 딥러닝이 있습니다. 가장 강력한 머신러닝의 툴로서 주목받는 딥러닝은 생각보다 어려��
www.fastcampus.co.kr
'딥러닝' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 37회차 미션 (0) | 2020.08.04 |
|---|---|
| [패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 36회차 미션 (0) | 2020.08.03 |
| [패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 34회차 미션 (0) | 2020.08.01 |
| [패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 33회차 미션 (0) | 2020.07.31 |
| [패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 32회차 미션 (0) | 2020.07.30 |



