[패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 14회차 미션
인공지능강의
05. PART 4) 딥러닝의 3 STEP의 기초
17. 쉽게 배우는 경사하강 학습법 - 05. (STEP 2) 심화 경사 하강법
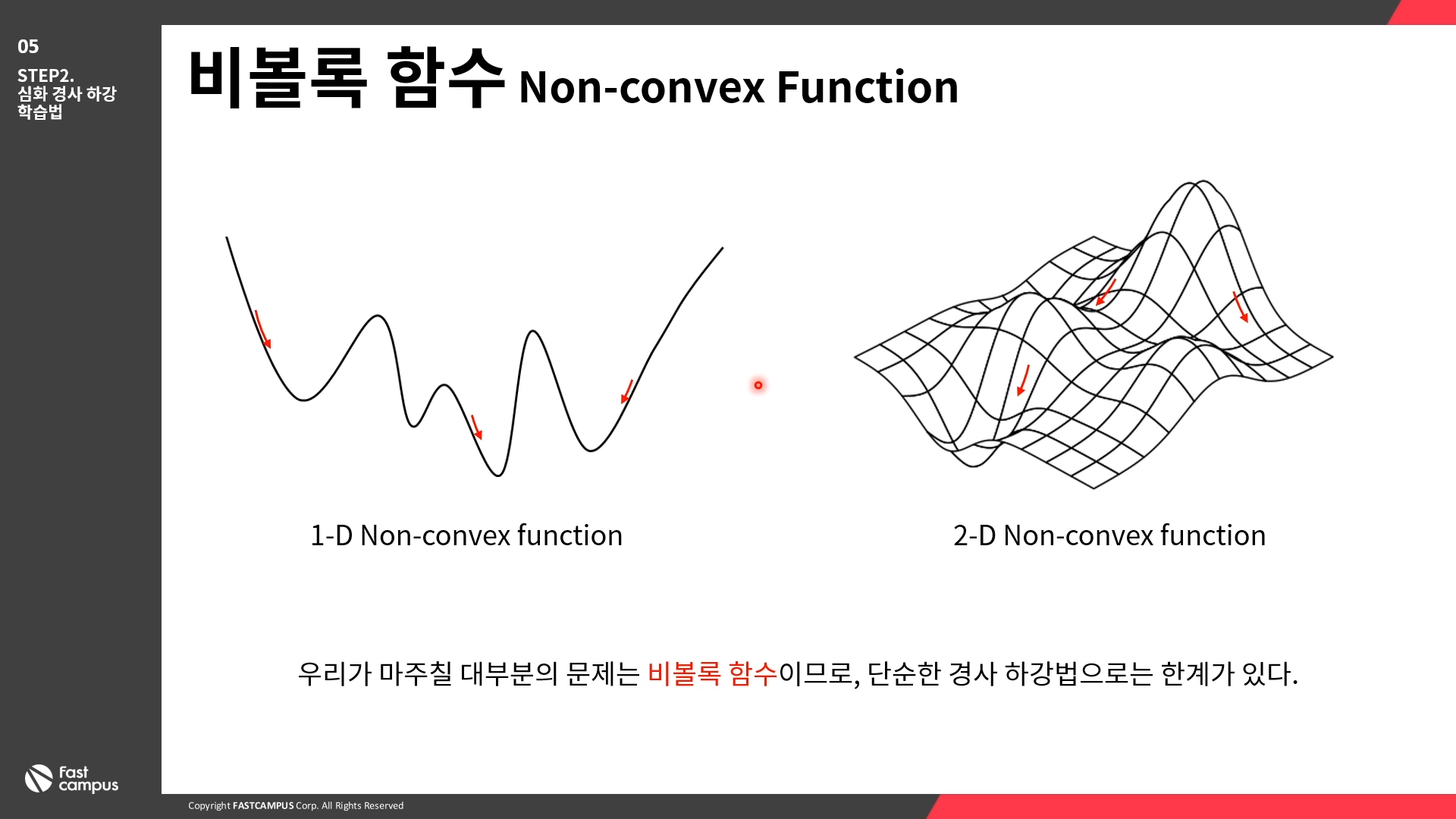



비볼록 함수 (Non-convex Function)
우리가 마주칠 대부분의 문제는 비볼록 함수이므로, 단순한 경사 하강법으로는 한계가 있다.
지역 최솟값 (Local Minimum)
경사 하강법을 사용할 경우, 초기값에 따라 Local minimum에 빠질 위험이 있다.
안장점 Saddle Point
안장점(Saddle Point)은 기울기가 0이 되지만 극값이 아닌 지점을 말한다.
경사 하강법은 안장점에서 벗어나지 못한다.
관성 Momentum
돌이 굴러 떨어지듯, 이동 벡터를 이용해 이전 기울기에 영향을 받도록 하는 방법
관성을 이용하면 Local minimum과 잡음에 대처할 수 있다.
이동 벡터를 추가로 사용하므로 경사 하강법 대비 2배의 메모리를 사용한다.
적응적 기울기 Adaptive gradient; AdaGrad
변수별로 학습율이 달라지게 조절하는 알고리즘. 기울기가 커서 학습이 많이 된 변수는 학습율을 감소시켜, 다른 변수들이 잘 학습되도록 한다. g_t가 계속해서 커져서 학습이 오래 진행되면 더이상 학습이 이루어지지 않는 단점이 있다.
RMSProp
AdaGrad의 문제점을 개선한 방법으로, 합 대신 지수평균을 사용 변수 간의 상대적인 학습율 차이는 유지하면서 g_t가 무한정 커지지 않아 학습을 오래 할 수 있다.
Adam
Adaptive moment estimation (Adam) RMSProp과 Momentum의 장점을 결합한 알고리즘. Adam 최적화 방법은 가장 최신의 기술이며, 딥러닝에서 가장 많이 사용된다.
18. 쉽게 배우는 경사하강 학습법 - 06. (STEP 3) 경사하강법을 이용한 얕은 신경망 학습 - 1
# 경사 하강법을 이용한 얕은 신경망 학습
import tensorflow as tf
import numpy as np
## 하이퍼 파라미터 설정
EPOCHS = 1000
## 네트워크 구조 정의
### 얕은 신경망
#### 입력 계층 : 2, 은닉 계층 : 128 (Sigmoid activation), 출력 계층 : 10 (Softmax activation)
class MyModel(tf.keras.Model):
def __init__(self):
super(MyModel, self).__init__()
self.d1 = tf.keras.layers.Dense(128, input_dim=2, activation='sigmoid')
self.d2 = tf.keras.layers.Dense(10, activation='softmax')
def call(self, x, training=None, mask=None):
x = self.d1(x)
return self.d2(x)
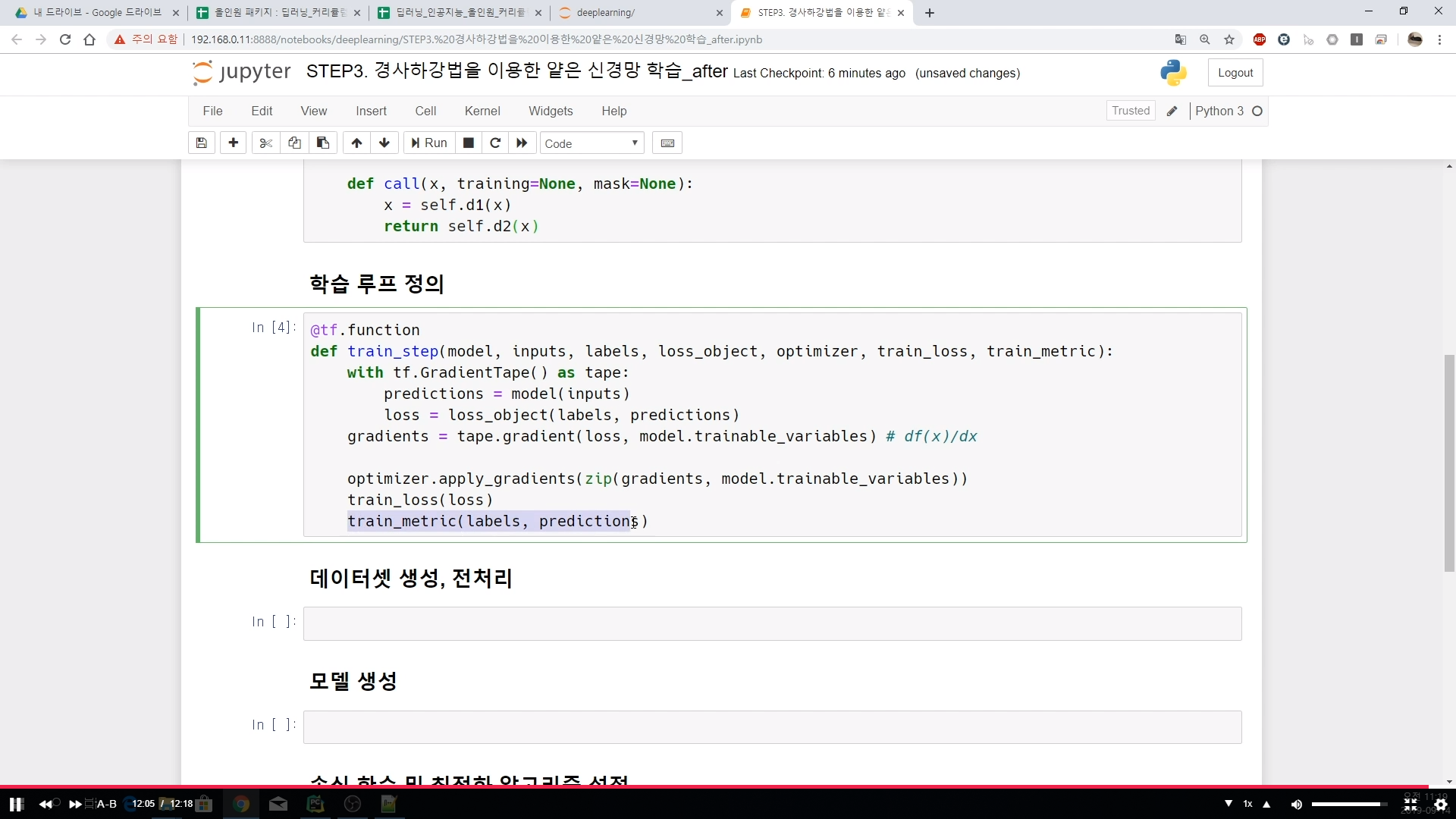
## 학습 루프 정의
@tf.function
def train_step(model, inputs, labels, loss_object, optimizer, train_loss, train_metric):
with tf.GradientTape() as tape:
predictions = model(inputs)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables) # df(x)/dx
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_metric(labels, predictions)
딥러닝/인공지능 올인원 패키지 Online. | 패스트캠퍼스
성인 교육 서비스 기업, 패스트캠퍼스는 개인과 조직의 실질적인 '업(業)'의 성장을 돕고자 모든 종류의 교육 콘텐츠 서비스를 제공하는 대한민국 No. 1 교육 서비스 회사입니다.
www.fastcampus.co.kr