[패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 55회차 미션
인공지능강의
PART 5) 딥러닝 최신 트렌드
39. Ch 04. 자연어처리 (Natural Language Processing) - 11. 자연어처리 대세 Transformer (실습) - 1
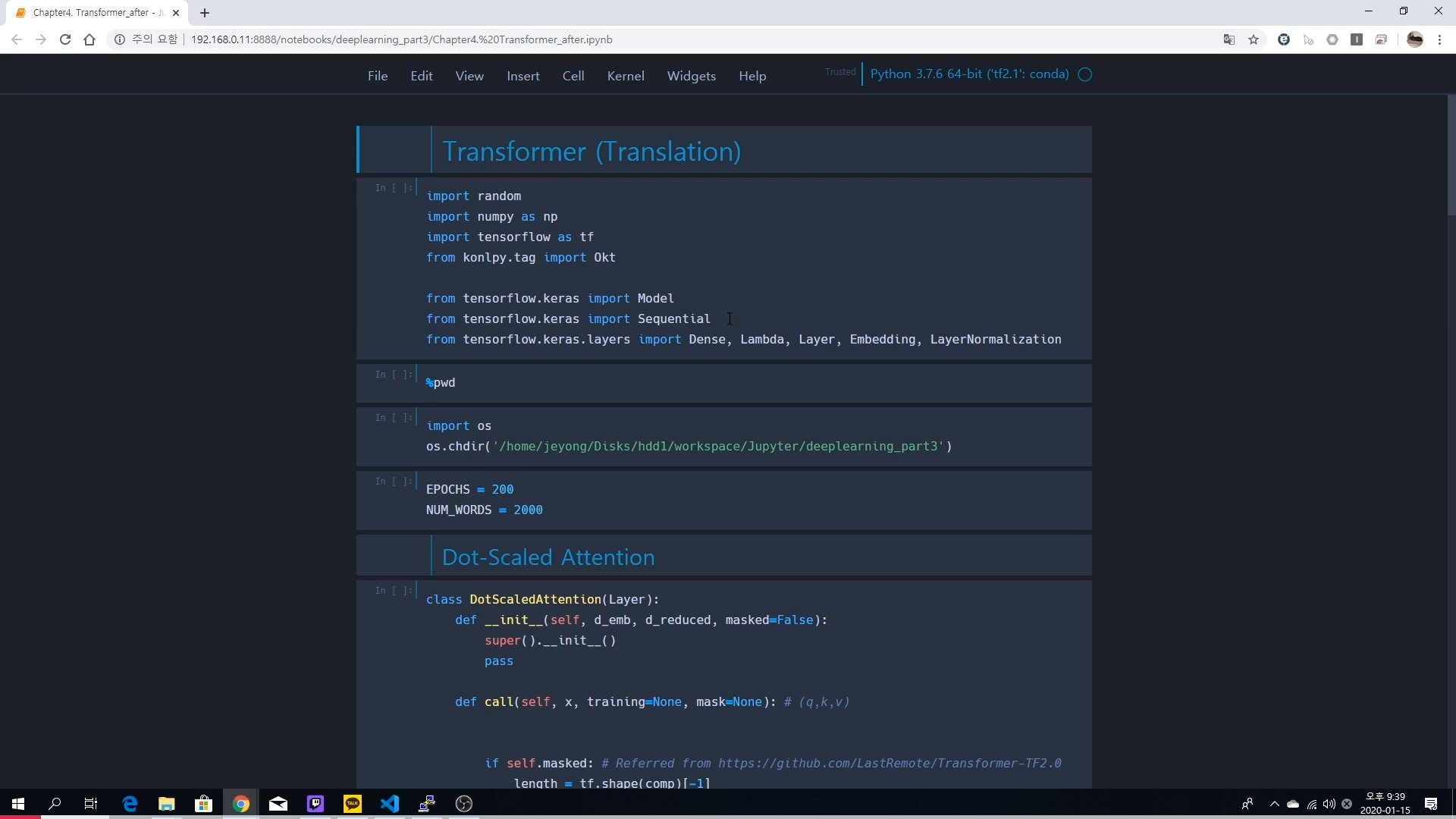

# Transformer (Translation)
import random
import numpy as np
import tensorflow as tf
from konlpy.tag import Okt
from tensorflow.keras import Model
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Lambda, Layer, Embedding, LayerNormalization
%pwd
import os
os.chdir('/home/jeyong/Disks/hdd1/workspace/Jupyter/deeplearning_part3')
EPOCHS = 200
NUM_WORDS = 2000
## Dot-Scaled Attention
class DotScaledAttention(Layer):
def __init__(self, d_emb, d_reduced, masked=False):
super().__init__()
self.q = Dense(d_reduced, input_shape=(-1, d_emb))
self.k = Dense(d_reduced, input_shape=(-1, d_emb))
self.v = Dense(d_reduced, input_shape=(-1, d_emb))
self.scale = Lambda(lambda x: x/np.sqrt(d_reduced))
self.masked = masked
def call(self, x, training=None, mask=None): # (q,k,v)
q = self.scale(self.q(x[0]))
k = self.k(x[1])
v = self.v(x[2])
k_T = tf.transpose(k, perm=[0, 2, 1])
comp = tf.matmul(q, k_T)
if self.masked: # Referred from https://github.com/LastRemote/Transformer-TF2.0
length = tf.shape(comp)[-1]
mask = tf.fill((length, length), -np.inf)
mask = tf.linalg.band_part(mask, 0, -1) # Get upper triangle
mask = tf.linalg.set_diag(mask, tf.zeros((length))) # Set diagonal to zeros to avoid operations with infinity
comp += mask
comp = tf.nn.softmax(comp, axis=-1)
return tf.matmul(comp, v)
40. Ch 04. 자연어처리 (Natural Language Processing) - 12. 자연어처리 대세 Transformer (실습) - 2


## Multi-Head Attention
class MultiHeadAttention(Layer):
def __init__(self, num_head, d_emb, d_reduced, masked=False):
super().__init__()
self.attention_list = list()
for _ in range(num_head):
self.attention_list.append(DotScaledAttention(d_emb, d_reduced, masked))
self.linear = Dense(d_emb, input_shape=(-1, num_head * d_reduced))
def call(self, x, training=None, mask=None):
attention_list = [a(x) for a in self.attention_list]
concat = tf.concat(attention_list, axis=-1)
return self.linear(concat)
## Encoder
class Encoder(Layer):
def __init__(self, num_head, d_reduced):
super().__init__()
self.num_head = num_head
self.d_r = d_reduced
def build(self, input_shape):
self.multi_attention = MultiHeadAttention(self.num_head, input_shape[-1], self.d_r)
self.layer_norm1 = LayerNormalization(input_shape=input_shape)
self.dense1 = Dense(input_shape[-1] * 4, input_shape=input_shape, activation='relu')
self.dense2 = Dense(input_shape[-1],
input_shape=self.dense1.compute_output_shape(input_shape))
self.layer_norm2 = LayerNormalization(input_shape=input_shape)
super().build(input_shape)
def call(self, x, training=None, mask=None):
h = self.multi_attention((x, x, x))
ln1 = self.layer_norm1(x + h)
h = self.dense2(self.dense1(ln1))
return self.layer_norm2(h + ln1)
def compute_output_shape(self, input_shape):
return input_shape
딥러닝/인공지능 올인원 패키지 Online. | 패스트캠퍼스
Tensorflow2.0부터 Pytorch까지 딥러닝 대표 프레임워크를 정복하기. 생활 깊숙이 침투한 인공지능, 그 중심엔 딥러닝이 있습니다. 가장 강력한 머신러닝의 툴로서 주목받는 딥러닝은 생각보다 어려��
www.fastcampus.co.kr