 [패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 35회차 미션
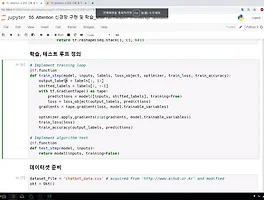
인공지능강의 05. PART 4) 딥러닝의 3 STEP의 기초 59. 맥락을 파악하는 Attention 기법 - 08. (STEP 3) Attention 신경망 구현 및 학습 - 2 ## 학습, 테스트 루프 정의 # Implement training loop @tf.function def train_step(model, inputs, labels, loss_object, optimizer, train_loss, train_accuracy): output_labels = labels[:, 1:] shifted_labels = labels[:, :-1] with tf.GradientTape() as tape: predictions = model([inputs, shifted_labels], training=..
[패스트캠퍼스 수강 후기] 인공지능강의 100% 환급 챌린지 35회차 미션
인공지능강의 05. PART 4) 딥러닝의 3 STEP의 기초 59. 맥락을 파악하는 Attention 기법 - 08. (STEP 3) Attention 신경망 구현 및 학습 - 2 ## 학습, 테스트 루프 정의 # Implement training loop @tf.function def train_step(model, inputs, labels, loss_object, optimizer, train_loss, train_accuracy): output_labels = labels[:, 1:] shifted_labels = labels[:, :-1] with tf.GradientTape() as tape: predictions = model([inputs, shifted_labels], training=..







